ElasticSearch를 이용한 검색 기능 만들어보기에서 백엔드에서 RDB에 데이터를 저장후에 ES인덱싱까지 해주는 과정을 거쳤었다. 이는 RDB에 저장후 ES로직에서 에러가 발생할경우 정합성이 안맞을 수 있다.
Debezium은 DB의 실제 변경사항을 토대로 Kafka메시지를 발행한다. 이를 통해 정합성을 어느정도 맞출 수 있다. 다음 과정을 통해 진행해보자.
적용과정
먼저 필요한 환경은 아래와 같다.
- mariadb
- elasticsearch
- zookeeper
- kafka
- debezium
해당 서버들은 docker를 통해 간단히 세팅해둘 수 있다. 아래 docker-compose.yml을 참고하자
version: "3.7"
services:
maria01:
image: mariadb:latest
command:
--server-id=1
--log-bin=mysql-bin
--binlog-format=ROW
container_name: maria01
restart: always
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: 1111
MYSQL_DATABASE: es
MYSQL_USER: user
MYSQL_PASSWORD: userpw
volumes:
- ~/data/mariadb:/data
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:8.14.0
deploy:
resources:
limits:
memory: 4g
container_name: es01
environment:
- discovery.type=single-node
- ELASTIC_PASSWORD=1111
- xpack.security.enabled=false
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- TZ=Asia/Seoul
ports:
- "9200:9200"
volumes:
- ~/data/es:/usr/share/elasticsearch/data
zookeeper:
image: confluentinc/cp-zookeeper:7.5.2
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "2181:2181"
volumes:
- ~/data/zookeeper:/var/lib/zookeeper/data
kafka:
image: confluentinc/cp-kafka:7.5.2
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT2://localhost:29092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092,PLAINTEXT2://0.0.0.0:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT2:PLAINTEXT
volumes:
- ~/data/kafka:/var/lib/kafka/data
connect:
image: debezium/connect:2.6
container_name: connect
depends_on:
- kafka
- maria01
- es01
ports:
- "8083:8083"
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
- CONNECT_KEY_CONVERTER=org.apache.kafka.connect.json.JsonConverter
- CONNECT_VALUE_CONVERTER=org.apache.kafka.connect.json.JsonConverter
- CONNECT_REST_ADVERTISED_HOST_NAME=connect
- CONNECT_PLUGIN_PATH=/kafka/connect,/usr/share/java,/etc/kafka-connect/jars
- CONNECT_DEBEZIUM_SNAPSHOT_MODE=initial
restart: alwaysDebezium이 DB에 접근하여 변경사항을 확인 후 Kafka메시지를 발행하기 위해서는 몇몇 권한이 필요하다. 때문에 아래와 같은 명령어를 통해 설정해주자.
# docker container 접근 명령어
docker exec -it maria01 mariadb -u root -p
# 권한 부여 명령어
GRANT REPLICATION SLAVE, REPLICATION CLIENT, BINLOG MONITOR ON *.* TO 'user'@'%';
GRANT RELOAD ON *.* TO 'user'@'%';
FLUSH PRIVILEGES;
- REPLICATION SLAVE: 바이너리 로그를 읽어 복제하거나 CDC를 수행할 수 있게 해준다.
- REPLICATION CLIENT: 복제 및 바이너리 로그의 상태 정보를 조회할 수 있게 해준다.
- BINLOG MONITOR: 바이너리 로그 이벤트를 읽을 수 있는 권한이다.
- RELOAD: 테이블, 로그, 권한 정보를 강제로 갱신할 수 있게 해준다.
- RELOAD: RELOAD은 Kafka Sink Connector를 통해 발행한 Kafka메시지를 컨슘해서 테이블을 수정할 예정이기 때문에 미리 넣어두자. 테이블, 로그, 권한 정보를 강제로 갱신(플러시)할 수 있게 해준다.
다음으로는 Debezium 커넥터를 Kafka Connect에 등록해서MariaDB의 job_posting 테이블에서 발생하는 변경사항(Insert/Update/Delete)을 Kafka 토픽으로 스트리밍하게 만드는 설정을 해줘야한다. 아래 명령어를 통해 할 수 있다.
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "mariadb-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "maria01",
"database.port": "3306",
"database.user": "user",
"database.password": "userpw",
"database.server.id": "184054",
"database.include.list": "es",
"table.include.list": "es.job_posting",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "dbhistory.fullfillment",
"include.schema.changes": "false",
"topic.prefix": "dbserver1"
}
}'여기까지 하고 DB에 데이터를 추가, 수정, 삭제를 한다면 카프카 메시지가 발행된 것을 볼 수 있다.
# 도커 컨테이너 접근
docker exec -it kafka bash
# 토픽 확인
kafka-topics --bootstrap-server localhost:9092 --list
# 메시지 확인
kafka-console-consumer --bootstrap-server localhost:9092 --topic dbserver1.es.job_posting --from-beginning
{
"schema": {
"type": "struct",
"fields": [
{ "type": "int64", "optional": false, "field": "id" },
{ "type": "string", "optional": true, "field": "company" },
{ "type": "string", "optional": true, "field": "location" },
{ "type": "string", "optional": true, "field": "category" },
{ "type": "string", "optional": true, "field": "title" },
{ "type": "string", "optional": true, "field": "description" },
{ "type": "string", "optional": true, "field": "requirements" },
{ "type": "boolean", "optional": true, "field": "is_deleted" }
],
"optional": false,
"name": "dbserver1.es.job_posting.Value"
},
"payload": {
"before": null,
"after": {
"id": 1,
"title": "백엔드 개발자",
"company": "테크 스타트업",
"location": "서울",
"category": "개발",
"description": "Spring Boot 기반 서버 개발 및 API 설계",
"requirements": "Java 3년 이상 경력 , Spring 경험자",
"is_deleted": false
},
"source": {
"version": "2.6.2.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 1750562152000,
"snapshot": "false",
"db": "es",
"sequence": null,
"table": "job_posting",
"server_id": 1,
"gtid": null,
"file": "mysql-bin.000002",
"pos": 4240,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1750562152114,
"ts_us": 1750562152114173695,
"transaction": null
}
}- before: 변경 전 레코드, Insert의 경우 null
- after: 변경 후 레코드
- op: 동작 타입 c = create, u = update, d =delete
실제 ES에 넣을 때는 이 중에서 after만 추출해서 넣는 경우가 많다. 이럴 때 사용하는 게 바로 Kafka Connect의 Transform 옵션 중 unwrap이다.
다음으로는 해당 메시지를 컨슘해서 DB를 갱신시키는 Kafka Sink Connector를 설정해야한다. 기존에 띄워놓은
debezium에 플러그인을 설치하여 진행해보자.
먼저 https://www.confluent.io/hub/confluentinc/kafka-connect-elasticsearch 사이트에서 zip파일을 다운로드 후 파일을 컨테이너 안의 kafka/connect 안으로 옮겨준 뒤 restart해야한다.
docker cp ./confluentinc-kafka-connect-elasticsearch-15.0.0 connect:/kafka/connect/
docker restart connect
# 플러그인 확인 명령어
curl http://localhost:8083/connector-plugins플러그인 확인 명령어를 통해
io.confluent.connect.elasticsearch.ElasticsearchSinkConnector가 있는지 잘 확인해주자.
다음으로는 아까와 비슷하게 Kafka 토픽(dbserver1.es.job_posting)에 쌓인 MariaDB 변경 데이터를 Elasticsearch로 자동 연동(동기화)하도록 Kafka Connect Sink 커넥터를 등록하는 과정을 거쳐야 한다.
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "es-sink-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "dbserver1.es.job_posting",
"connection.url": "http://es01:9200",
"type.name": "_doc",
"key.ignore": "true",
"schema.ignore": "true",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}'
tasks.max옵션을 통해 실행될 최대 태스크 개수를 조절하여 병렬 처리도 할 수 있다.
key.ignore는 Kafka 메시지의 key 값을 무시할지 여부를 결정한다. (true는 무시) 보통 Debezium의 메시지는 key가 따로 필요하지 않으므로 true로 설정한다. 왜냐하면, 대부분의 ES 연동 실무에서는 ES의 document ID는 자동 생성하거나 Debezium value에서 따로 ID 필드를 지정해서 사용하기 때문이다. 즉, Debezium 메시지의 Kafka key를 굳이 ES의 document ID로 직접 매핑하지 않는다.
schema.ignore는 Kafka 메시지의 스키마 정보를 무시할지 여부를 결정한다. true로 하면 스키마 정보 없이 값만 사용. Debezium은 기본적으로 schema 포함, ES에는 주로 값만 넣기 때문에 true를 권장한다.
transforms에는 여러가지 옵션이 있으니 상황에 따라 맞춰 사용하자.
"transforms": "unwrap,createKey,addField", 이런식으로 여러개도 적용 가능하다는 점 참고하자.
| unwrap | "transforms": "unwrap" | Debezium 메시지에서 after만 추출 |
| createKey | "transforms": "createKey" | value의 특정 필드를 key로 복사 |
| addField | "transforms": "addField" | value에 새 필드 추가 |
| replace | "transforms": "replace" | 불필요/민감 필드 제거 |
| mask | "transforms": "mask" | value의 특정 필드 마스킹 |
| tsConvert | "transforms": "tsConvert" | 타임스탬프 포맷 변환 |
| hoist | "transforms": "hoist" | value 전체를 특정 필드로 래핑 |
| route | "transforms": "route" | 토픽명 패턴 변경(라우팅) |
결과
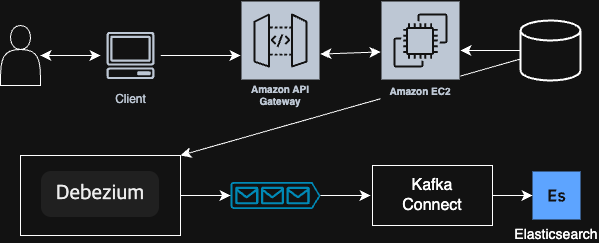
여기 까지 했다면 모든 세팅이 완료되어 위 와 같은 구조가 된것이다.
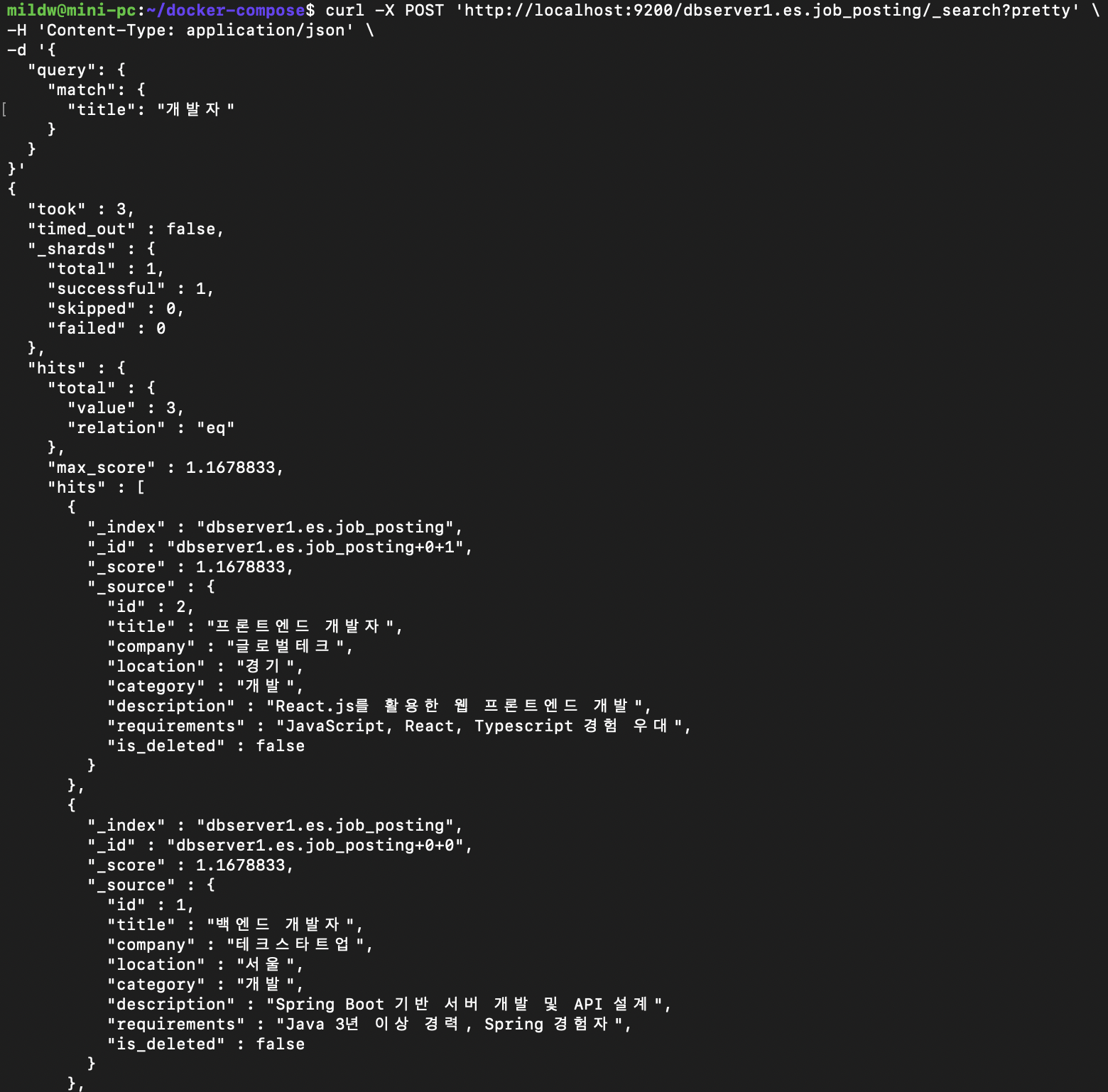
실제로 ES에 요청하여 검색결과를 볼 수 있었으며,
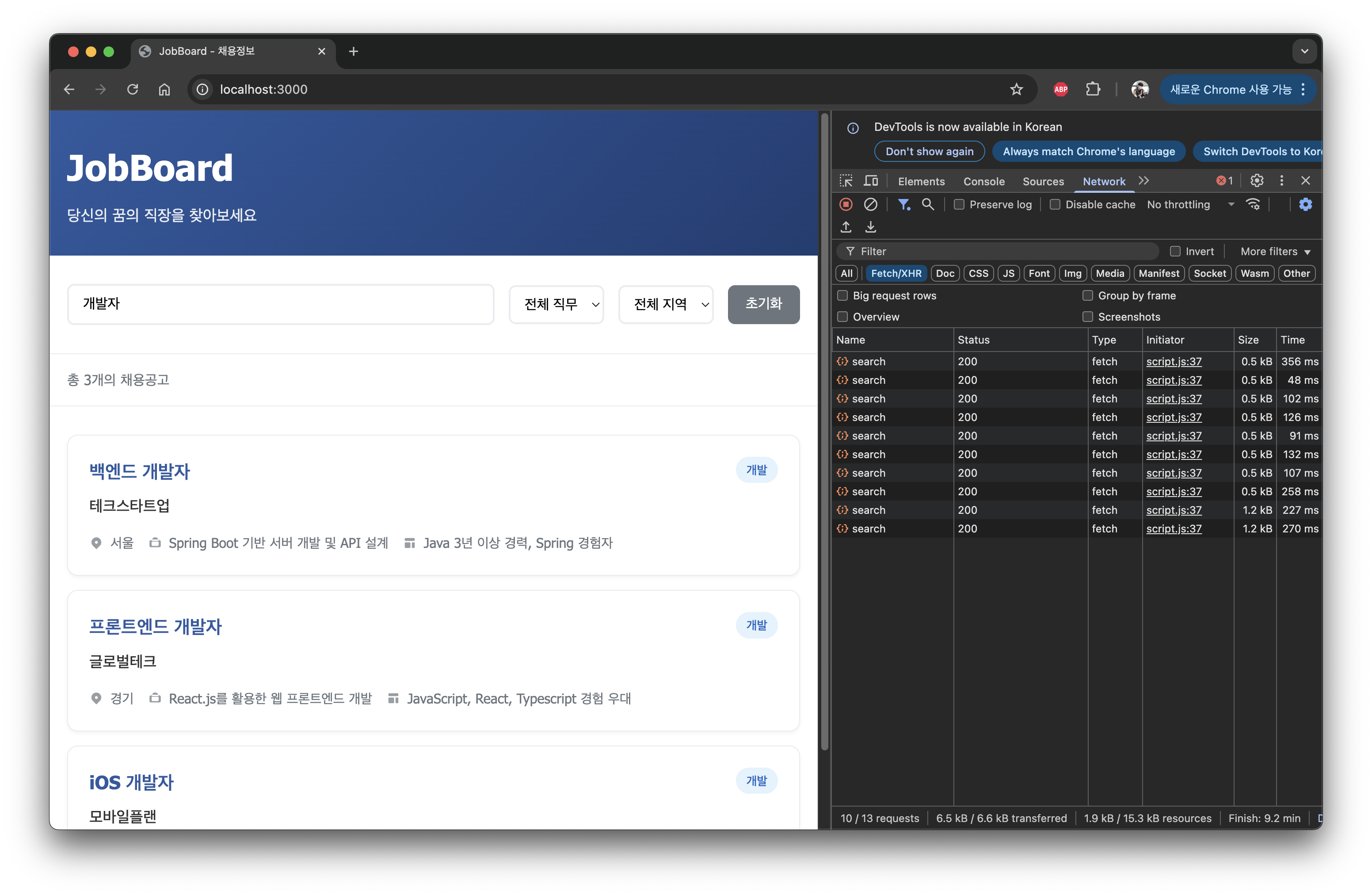
페이지도 잘 뜨는것을 확인 할 수 있었다.
우려되는점
Debezium을 사용하면서 우려해야할 몇몇 점들이 있다. 특히 DB 컬럼 변경 후 ES 인덱스 매핑을 갱신하지 않는다면 에러가 발생하고, Sink Connector가 지속적으로 적재 실패할것이다. 또한 ES 서버의 순간적 다운타임으로 인한 적재 실패 및 Connector 장애가 발생할 수 있다.
이런 이슈를 예방/조치하기 위해, Connector의 `Dead Letter Queue` 기능을 활용하여 실패 건을 별도 토픽에 저장하고, Kafka, ES, Connector의 장애/에러를 Slack/Email 등으로 실시간 알림과 ES, Kafka, DB 스키마/매핑을 사전에 주기적으로 검증이 필요하겠다.
'Web' 카테고리의 다른 글
| Rag를 사용해서 자신의 전문 비서를 만들어 보자 (5) | 2025.07.08 |
|---|---|
| MSA에 꼭 필요한 Terraform 사용해보기 (2) | 2025.07.05 |
| ElasticSearch를 이용한 검색 기능 만들어보기 - 1 (1) | 2025.06.20 |
| ElasticSearch를 이용한 검색 기능 만들어보기 - 0 (0) | 2025.06.18 |
| [book] 스프링으로 시작하는 리액티브 프로그래밍 - 0 (2) | 2025.06.11 |