개발시작
오늘의 목표는 ES를 활용하여 JobBoard 사이트를 개발하는것이다. 간단한 조회기능부터, SwaggerUI를 통한 create, update, delete기능까지 만들것이다.
먼저 간단한 사이트부터 만들어보자. 요즘 AI는 간단한 프론트 페이지 정도는 가볍게 구현해주니. AI를 활용해서 HTML, CSS, JS를 통해 페이지를 하나 만들었다.

먼저 데이터 모델을 설계하고 해당 모델을 토대로 더미를 넣어 어떤식으로 출력된는지 확인한다. 위의 사진 정도면 어느정도 몰입해서 할 수 있을 것 같다.
다음으로는 백엔드 개발을 진행해야한다. 백엔드 프로젝트의 구조는 아래와 같다.
.
├── application
│ └── service
├── common
│ └── config
├── domain
│ ├── model
│ ├── repository
│ └── service
├── infrastructure
│ ├── config
│ ├── entity
│ └── repository
└── presentation
└── controller클린 아키텍처 구조를 통해 개발하려고했다. 클린 아키텍처는 소프트웨어를 여러 계층으로 분리하여, 핵심 비즈니스 로직(엔티티)이 외부 요소(UI, DB 등)에 영향을 받지 않도록 설계하는 아키텍처이다. 모든 의존성은 바깥에서 안쪽으로만 향하며, 이를 통해 관심사의 분리, 낮은 결합도, 높은 테스트 용이성, 유지보수와 확장성을 달성할 수 있다. layer간의 객체 매핑은 mapstruct를 통해 깔끔하게 진행할 수 있다.
먼저 조회 로직을 살펴보자.
public SearchResponse<JobPostingEsDoc> searchIds(String keyword, int page, int size) {
try {
return esClient.search(s -> s
.index("jobposting")
.size(size)
.from(page * size)
.query(q -> q.match(m -> m.field("title").query(keyword))),
JobPostingEsDoc.class);
} catch (IOException e) {
throw new RuntimeException(e);
}
}해당 로직은 JobPostingEsRepository.class중 일부이다. 페이징 처리를 포함한 Es의 간단한 조회로직을 통해 Es로부터 값을 받아온다.
public JobPostingSearchRs findBySearch(PostingSearchRq rq) {
SearchResponse<JobPostingEsDoc> response = jobPostingEsRepository.searchIds(rq.getQ(), rq.getPage()-1, rq.getSize());
List<Long> ids = response.hits().hits().stream()
.map(hit -> hit.source().id())
.toList();
List<JobPostingDto> jobPosting = jobPostingDomainService.findByIds(ids).stream().map(jobPostingDtoMapper::toDto).toList();
return new JobPostingSearchRs(jobPosting, rq.getPage(), rq.getSize(), response.hits().total().value());
}이후 JobPostingService.class에서 JobPostingEsDoc Response를 받아 id List를 통해 RDB로 요청하여 JobPosting데이터를 받아온다. JobPostingEsDoc에도 동일한 값이 있겠지만, 이렇게 한 이유는 실무에서는 RDB로부터 값을 가져와 사용해야 할 (댓글, 좋아요 등)정보 등 이 있을 것이기 때문에 이렇게 코드를 구현해봤다.
또한 트랜잭션이 분리되어, RDB에 먼저 저장하고 이후에 Es에 저장하는 방식이기 때문에, 특정 구간에서 RDB와 Es의 정합성이 안맞을 수 있으므로 유의해야한다. 이 때문에 실시간성이 필요한 데이터는 RDB로부터 데이터를 가져오고 Es는 필터 역할만 하도록 한다.
public void save(JobPosting jobPosting) {
JobPostingEsDoc doc = jobPostingMapper.toEsDoc(jobPosting);
try {
IndexResponse response = esClient.index(i -> i
.index("jobposting")
.id(String.valueOf(doc.id()))
.document(doc)
);
} catch (IOException e) {
throw new RuntimeException(e);
}
}Debezium을 사용하기 전 단계이기 때문에, 테스트용으로 코드상에서 데이터 저장시 Es의 인덱스를 갱신해 주도록 코드를 구현해 놨다.
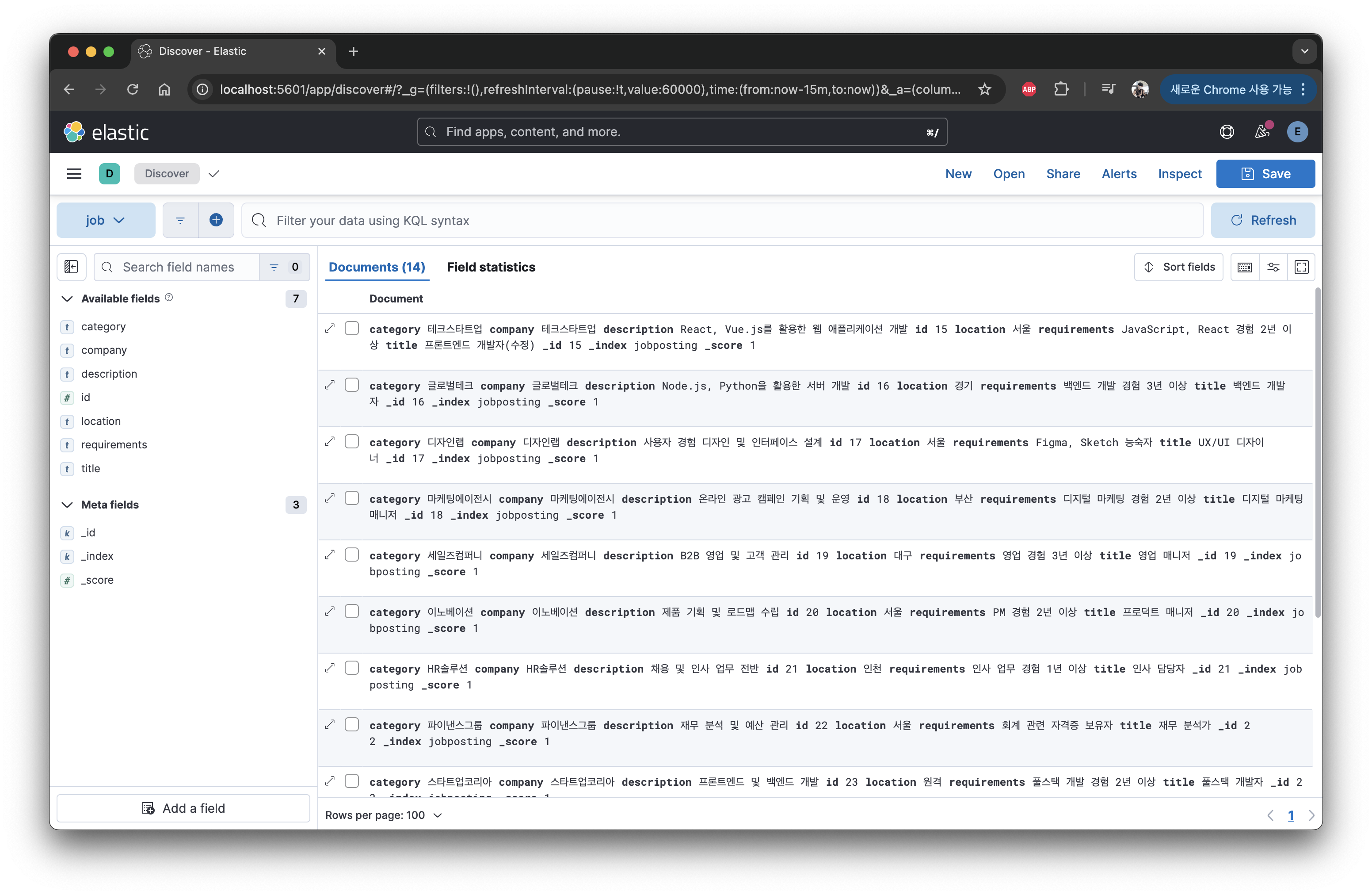
데이터 저장하면 위 사진과 같이 Es에 저장된 것을 볼 수 있다.
결과
이와 같은 과정을 통해

Es를 활용하여 간단한 JobBoard의 검색기능을 만들 수 있었다. 실무에서는 더 복잡한 필터링과 비즈니스 로직이 있겠지만, Debezium을 사용하여 데이터가 갱신되는것을 먼저 보고싶으니 나중에 개선해 볼 예정이다.
Debezium은 코드 오류, 네트워크 장애 등으로 인해 RDB에는 저장됐지만 ES에는 누락/지연되는 동기화 문제를 해결할 수 있다 또한 DB의 로그에서 직접 변경 이벤트를 추출하기 때문에 실제로 커밋된 변경사항만 감지하므로, “DB와 100% 일치”를 목표로 할 수 있다.

이로써 위와같은 비슷한 구조가 (API Gateway는 없지만)완성됐다. 다음으로는 Debezium을 사용해서 데이터를 갱신시키고 갱신된 데이터를 조회하는것 까지 진행해보자.
진행하면서 발생한 문제
Es를 쓰다보니 한글에 대한 검색시 형태소 분석기에 문제가 있었다. 해당 문제는 "개발"이라고 검색하면, "개발자"도 포함되어 검색이 되어야하는데 그렇지 않았던 이슈이다. 이를 해결하기위해 nori라는 형태소 분석기 플러그인을 설치하고 적용했다.
docker exec -it <es-container-id> bin/elasticsearch-plugin install analysis-nori
docker restart <es-container-id>본인은 도커를 사용하고 있으므로 컨테이너에 접근해서 직섭 install 해주는 과정을 거친 후에 컨테이너를 restart 하여 설치를 완료했다. 유의할점은 해당 플러그인을 적용하기 위해서는 인덱스를 지우고 다시 PUT해야 한다는 점이다.

하여 위와같은 명령어 처리를 거친 후에야 "개발"을 입력해서 개발자와 연관된 데이터들을 리턴받을 수 있었다.
'Web' 카테고리의 다른 글
| MSA에 꼭 필요한 Terraform 사용해보기 (2) | 2025.07.05 |
|---|---|
| ElasticSearch 인덱스 갱신을 위한 Debezium 사용해보기 (1) | 2025.06.22 |
| ElasticSearch를 이용한 검색 기능 만들어보기 - 0 (0) | 2025.06.18 |
| [book] 스프링으로 시작하는 리액티브 프로그래밍 - 0 (2) | 2025.06.11 |
| 헥사고날 아키텍처에 관한 생각 (1) | 2025.06.09 |